We attended the Data-Driven Everything virtual event hosted by Amazon on September 5. The hands-on sessions were a helpful deepdive into understanding and using Amazon's Bedrock ecosystem for building AI agents. Details below.
Using Amazon Q to generate SQL code
Amazon Q is Amazon's generative AI assistant for AWS developers. The hands-on session involved accessing preloaded databases and tables in Redshift, activating the Q Generative SQL asisstant, and prompting the assistant to generate SQL code (e.g. "Who are our most valuable customers based on total order amount"). The SQL code can then be copied to the notebook (SQL editor). You can then run the query and see the output. We have a screenshot below of what the interface looks like.
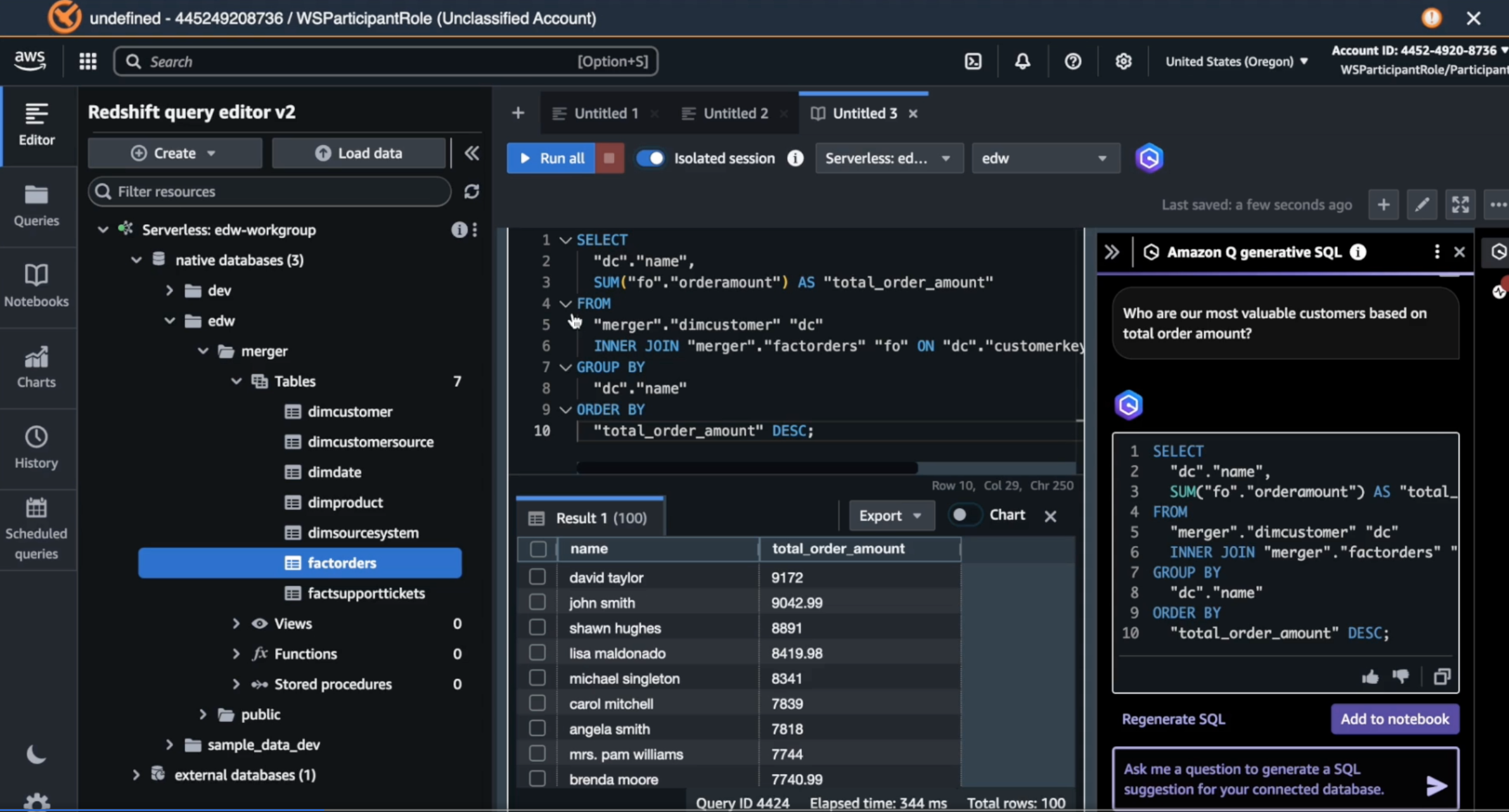
The left and center panels are the standard Redshift interface, with the database and table directory on the left, and the SQL editior in the center. To the right you have the Amazon Q assistant that generates SQL. We found this to be a very quick and efficient way to generate custom SQL queries that uses schema and context from one's tables. You also don't need to preface your prompt with something like "Write me a SQL query that ...". You just ask your question and it will generate the SQL query that, when executed, gives you the answer.
Using Amazon Bedrock Knowledge Bases to get readable responses to prompts querying a database
Amazon Q responds to your prompt with a SQL rather than a human-readable response. As an example, if you ask it "who are our most valuable customers?", it will give you a SQL query that you have to run on Redshift to get the answer. If you want to go from prompt to answer directly, you will need to set-up Amazon Bedrock Knowledge Bases. As with all things AWS, configuration is key, and this is where the hands-on sessions are very helpful. After creating a knowledgebase, you have to configure it to use Redshift as the query engine, IAM for permissions, and point it to the right Redshift databases. Once the Knowledge Base is created, you have to select the model (e.g. Amazon Nova Pro). You can now test the Knowledge Base by prompting it with a question (e.g. Who are our most valuable customers). In this case, the Knowledge Base will generate a readable response that gives you the answer. You can click on the footnote to see the query used to generate the response. A screenshot of the UI is shown below
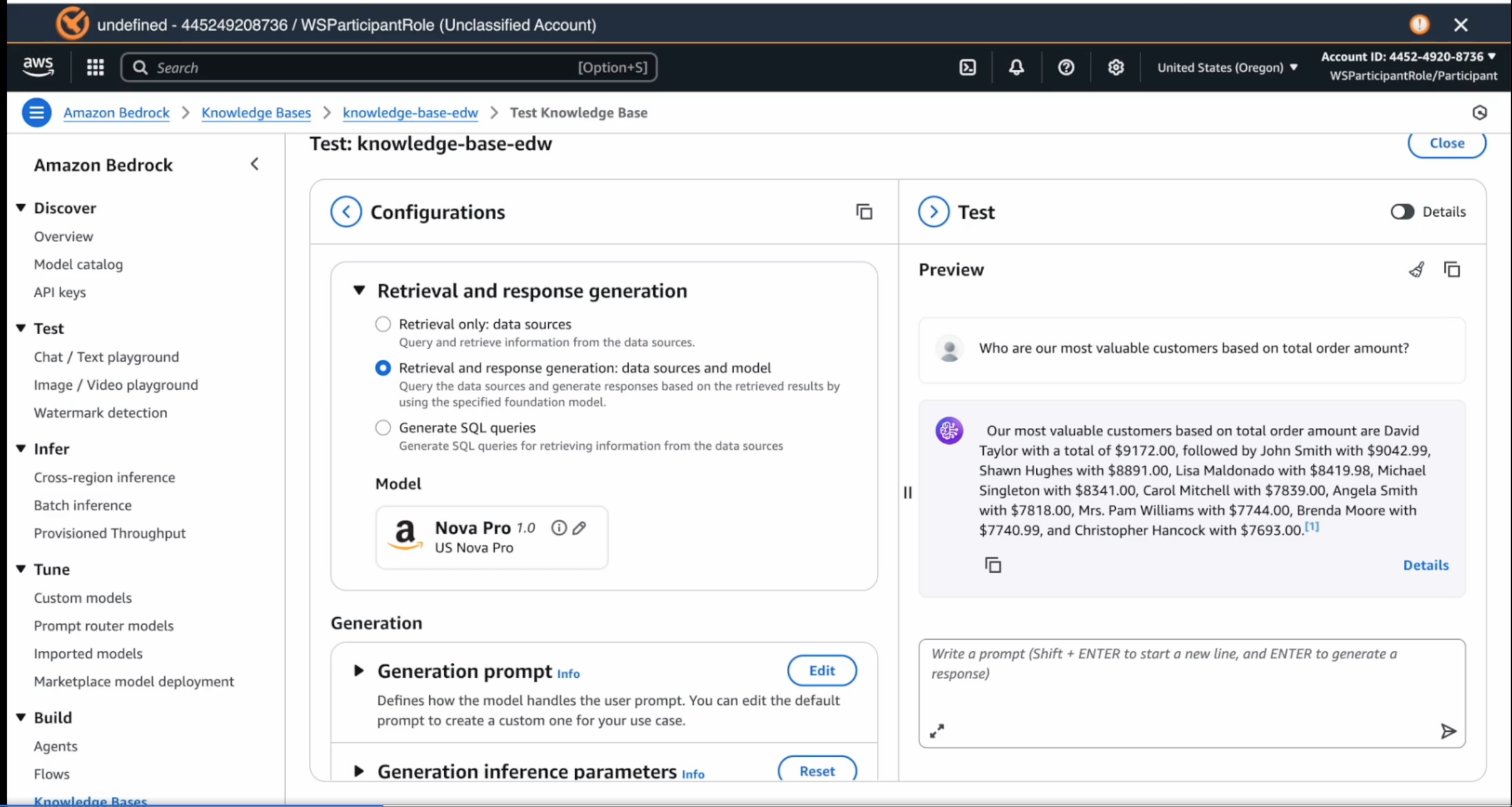
In the top right quadrant is the chat interface where one can type in the prompt and get a readable response. The top left quadrant shows the model selected - in this case, Amazon Nova, though there are a host of other models that you can pick and choose from.
One can also create Knowledge Bases for unstructured data such as customer support message tickets, product manuals, among others. To do so, you can choose to set-up the knowledge base as a vector store. You can select S3 (instead of Redshift) as your data source, and browse S3 to point to the S3 bucket that has your unstructred data. You will need to select an embeddings model to convert your data into embeddings, and you can choose from several different options for doing so. You can further choose a vector store type (e.g. Amazon OpenSearch Serverless, Amazon S3 vectors). Once created and set-up, you will need to pick an LLM model in the test interface, and then you can query your vector store to get responses. A screenshot of the UI is shown below
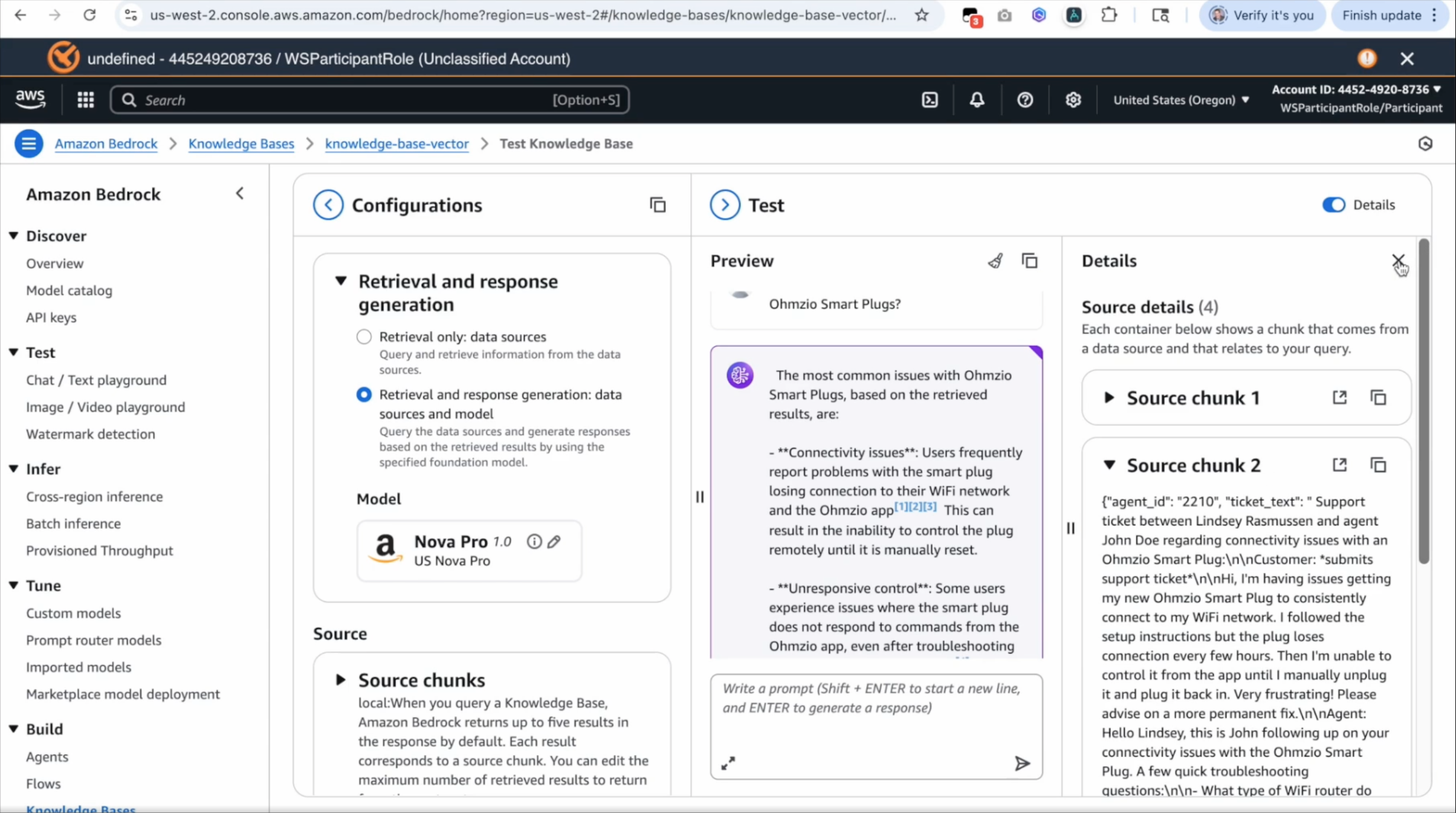
As before you can see the chat screen in the right half that you can use to interact with the model. The example in the screenshot is of a prompt query to get the most common issues with Ohmzio smart plugs (a fictional product). The foundational model in turn relies on the vector database that contains chunks of customer support tickets to come up with a response. The response includes hyperlinks that reference the chunks of data. You can click on the hyperlink to review the data sources, as shown on the right side of the image above.
A follow-up prompt can be to ask for an update to the product documentation to resolve the specific issue. The model uses a combination of support tickets and product manuals to come up with a response.
As a quick aside, to be able to do what we did in the above example pre-LLMsm, it would have taken a few different NLP models - one for text classification to classify support issues, another to summarize responses for issue sub-types to be able to generate updates to the documentation and so on. Each of the prompts above would be its own ML workflow with associated models. The remarkable thing about LLMs working on your own data is that once set-up properly, you can now achieve what would have taken weeks of work by a data scientist in just a matter of minutes.
Chatbot AI agent with Amazon Bedrock
Amazon Bedrock Agents lets you build an agent that connects to the previous knowledgebases on structured and unstructured data that you have created. The example scenario involves building a customer support chatbot that is meant to be used by customer service representatives as they handle customer inquiries. The agent set-up process involves naming the agent, and connecting to the two knowledge bases that we have created above. You can now test the agent with a prompt query (e.g. "My customer has an issue with the Smart Pet Feeder dispensing the correct amount of food. What should I do?"). The agent will provide a response with step-by-step instructons. As a developer of the chatbot, you can click on the trace that shows how the information was retrieved, and how the response was generated.
The agent currently allows access to all of the data, and if you want to limit access to specific information (e.g. customer address), this can be done using Amazon Bedrock Guardrails. In addition to limiting PII access, you can block harmful user inputs and model responses, block prompt attacks, denied topics (e.g politics) including sample questions you don't want the models to answer, word filters (block profanity) among others. For PII, you can specify PII type (e.g. name, address, phone number). You can choose to block or mask PII both in user input and response. Once the guardrail is created, you can associate it with your agent, and test the agent using the chat interface to see if the guardrails are working as expected.
Visual Builder for AI applications
The final session was on Amazon Bedrock Flows - a visual drag-and-drop builder for AI applications. It lets you drag blocks such as for knowledge bases and agents, configure and link them, and setup an AI agent. Flows is a standalone framework that is a distinct way of setting up AI agents from how we had gone about it in the prior sections. It is aimed at users who prefer a simple user interface to set up AI agent flows. The UI for Flows looks as below
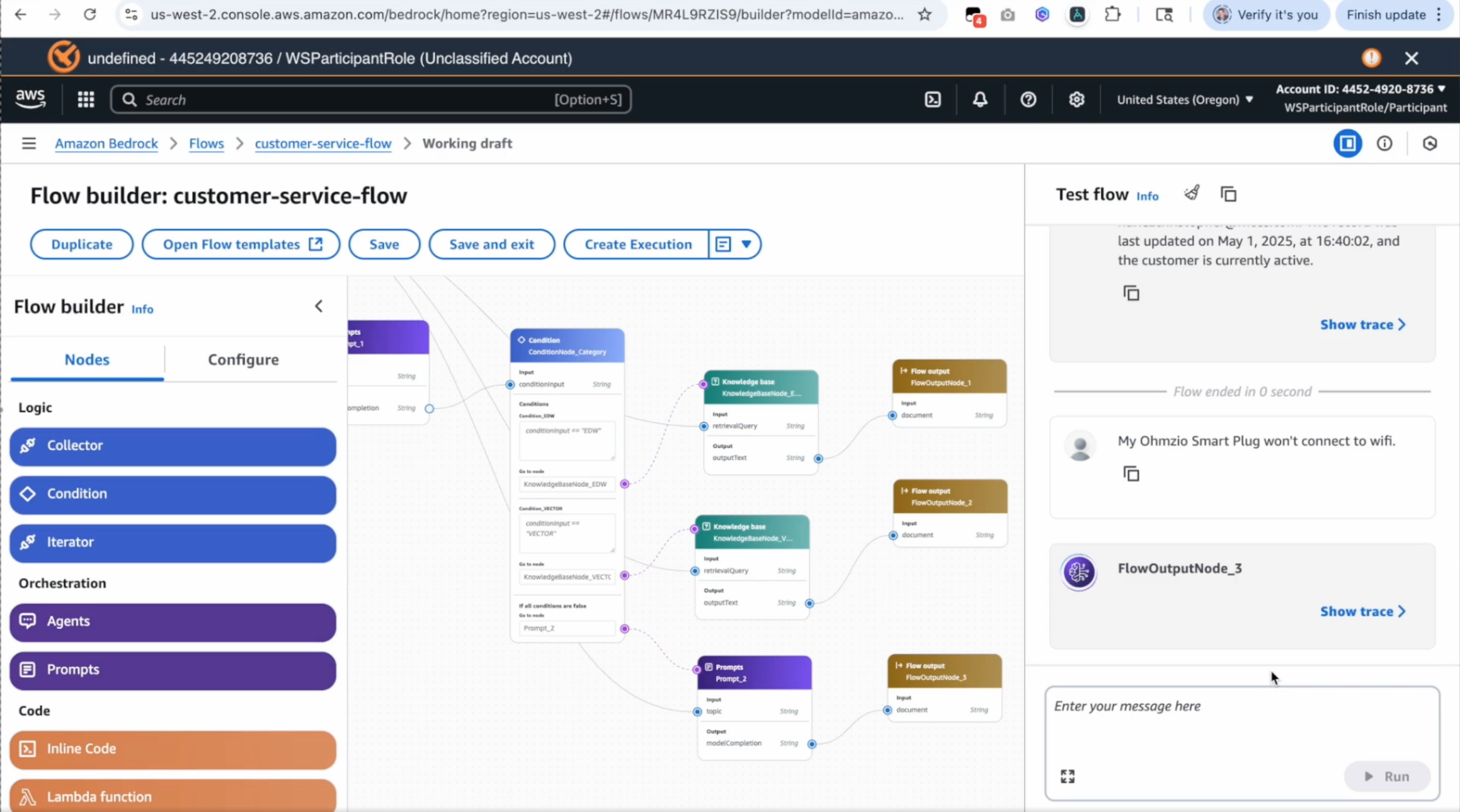
--
In addition to the above, the session discussed Prompt Management though it didn't clarify how this is configured into an agent. Bedrock also has Action Groups that let's users complete actions (e.g. create a booking or cancel a booking), but didn't get into much detail.
Overall, we found the session to be quite useful, and a good complement to the sessions at Generative AI Day about which we had posted previously. Amazon's Agentic AI stack is still seemingly complex. During the Generative AI Day sessions, they had highlighted Amazon Bedrock as the simpler approach to build and deploy AI agents, with Sagemaker AI being the more flexible and configurable set-up that supports custom ML models. In the session on Bedrock today, we find a further 2 ways of building agents - one using Bedrock Agents, and the other using Bedrock Flows. In essence, Amazon AWS offers 3 paths to building Agentic AI applications starting with the simplest:
- Amazon Bedrock Flows: This is a simple drag-and-drop visual interface for building AI agents. It targets low-code users who prefer a visual drag-and-drop interface
- Amazon Bedrock Agents/AgentCore: This is a relatively more configuration heavy path to build and deploy AI agents using pretrained foundation models (FM). It is targeted at AI developers who prefer to work with pre-trained FMs and using it alongside their data in a RAG set-up for custom AI applications.
- Amazon Sagemaker AI: This is a code-heavy set-up for those interested in building or finetuning foundation models targeted at ML engineers and data scientists with a background in training and deploying models on large volumes of data
Put another way, the simpler approaches of using Bedrock Flows or Agents is a quick way to prototype an MVP for an AI application, and test it. You can then use Sagemaker AI to level it up further.